Vectors and Lines
Vectors have magnitude and direction in (-tuple)
Line in can be represented as
Linear Combination
of a set of vectors is the set of all possible linear combination of those vectors
- If the vector is 0, span is a point of that vector
- span of 1 vector is a line
- span of 2 vectors, where one is a lin comb of the other, is still a line
- Called linearly dependent
- if linear combination of ‘covers’
- of will guarantee that 1 of them is redundant (lin comb of some others)
Linear Dependence
A set of vectors is linearly dependent iff there is a linear combination that results in with one of the constants being non-zero:
Else, linearly independent.
Do systems of equation on example case to determine if it’s possible to write any vector as a lin combination of your vector set. Once you have an equation, see what the factors need to be to create a , if they are all , then lin independent.
Subspace
The set of vectors is a subset of
It is a subspace of if:
- Contains
- (closure under multiplication)
- (closure under addition)
Note: span of set (lin comb) is a subspace
BASIS
If is a subspace , its basis is a minimal set that spans .
Minimal meaning linearly independent.
- Any set that spans must have at least size of
- Proof: If you have some set that spans and has less members than , you can replace members of 1-by-1 with because members of will be able to be re-written as lin combinations of and you end up with a contradiction.
- size of any basis
- ex. If vectors are in but basis size is 2, the subspace only spans
- Vector in some basis :
- TODO: change of basis (inverse)
Vector Length and Product
(scalar)
(Cauchy Shwarz inequality)
- Remove the squares
- Triangle Inequality
- Geo intuition: vector formed by traveling from first to second will have length less than or equal to individual lengths’ sum (equal if vec is same)
(Law of Cosines, triangle geo in n-dim)
- Expand using dot product definition on lhs
- So, if , then are orthogonal!
; normalized unit vector
Planes
In , if you have a point on the plane and take any other point on that plane , then a vector on that plane will be . A normal vector to that plane will mean that .
This means that
Then, for a fixed/known you will get an equation that looks like
Where are coordinates of and are coordinates of .
Something something about calculating point distance to plane
Something something about calculating distance between two planes
Matrices
Basic definition
Row view:
Column view:
This is now a linear combination of the column vectors of $A$.
Null space
- The set of vectors that satisfy this is a subspace (refer to properties of subspace)
- Given an , find rrech form, write as a linear combination with free variables, can be written as
Connection with linear independence
is the set of all s.t.
where are column vectors of .
Then from the definition, are linearly independent if the only solution to the above is
Column space
- Like null space, this is also a subspace
- Reminder about being all possible linear combinations of the vectors
- If this means the cols are linearly independent, so they form a basis for .
- Dependent ones will be the free variables of after rref
- You can show that you can write those columns of as lin. comb. of the others by setting the remaining free variables to
- therefore they are redundant and the basis is the remaining columns
- Something something about plane equation from the basis
- i.e. find the size of the basis of ) (number of pivot cols of rref)
Properties of matrices
; where 0 is a matrix of zeros
;
In general
It could be that even if and
so, some things are not like scalars
Diagonal Matrix
Identity Matrix
Matrix Decomposition
Let matrix with a 1 in position and 0’s elsewhere. Then we have
Then, we can write matrix multiplication as:
Inverse
An inverse matrix is one where the following holds:
How to find it? Use adjoint of called :
Then:
Define .
Now, if , then we can find that
Some findings
1-1 functions and Null Space
A function that is 1:1 means it’s inverse is also a function (functions may map many-one, meaning inverse is not a function).
Reminder on Null Space
If has a non-trivial solution, then is a many-one function.
Proof: for any , we can add this to any solution.
Linear Transformations/Functions
A transformation is linear if it satisfies
or all in one
We can show that is a linear transformation: :
(distributive rule)
Matrices are Linear Transformations
Given that is rows by columns
AND it is a linear transformation.
Function composition is Matrix Multiplication
Exploring Matrices as Linear Transformations
Dilations: Diagonal matrices (stretch initial vector)
Rotations: TODO
- From 3blue1brown:
- Matrix cols are what happened to the basis vectors (ihat jhat)
- Doing the same thing that happened to the basis vectors onto some new vector
Where at the end, is a matrix where the columns are the basis vectors with the transformation applied to them. At the beginning, is any linear transformation.
Projection Onto Line
Pick any , and project onto a line that is drawn by .
Projection formula origin. Note that is what we want to find.
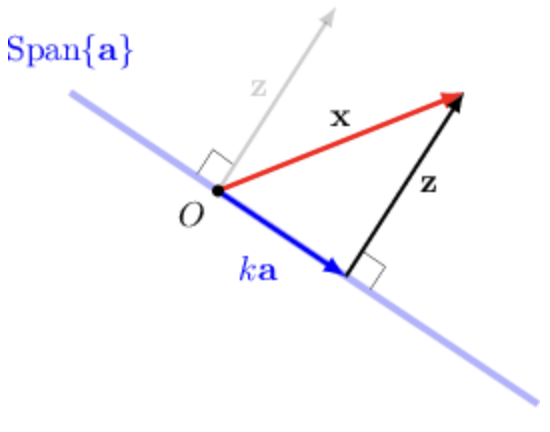
Multiply by both sides, and due to we get:
Therefore our goal, projection of onto is:
If is a set of orthogonal vectors, then the orthogonal projection of a vector onto the subspace is given by
In other words, the orthogonal projection of onto is the sum of the orthogonal projections of onto each one-dimensional subspace of .
Watch out! The formula works only when the set of vectors is orthogonal!
In the case of a 2-dimensional subspace , we can visualize the orthogonal projection geometrically, as follows:
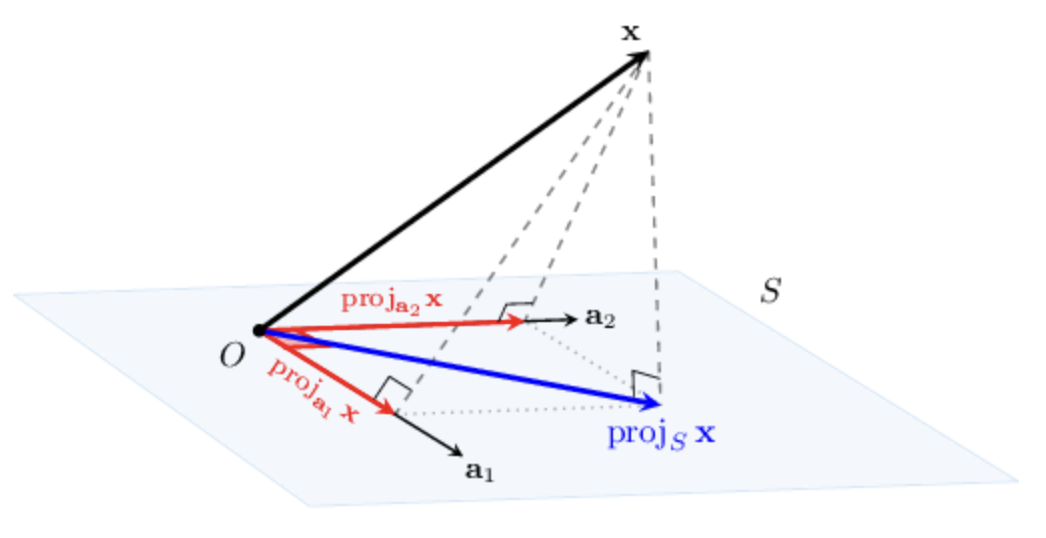
Projection Onto Any Subspace
GOAL: Find the orthogonal projection of the vector onto the subspace
- Notice that since , the vectors and are not orthogonal.
Write as
where and .
Step 1: Projection Relation
Since , that is, ,
Step 2: System of Equations
Now, we substitute the expression for into the system to get
We can write this system in an equivalent matrix form as follows:
Step 3: Matrix Representation
Denote
then
Therefore,
This is a formula for the orthogonal projection!
Comparison with line projection
The orthogonal projection of a vector onto the one-dimensional subspace is given by
we can re-write it like:
Linear and Bilinear Forms
Linear form: where .
Bilinear form:
Suppose is an matrix. Then, the function defined as
is linear in each argument separately. That’s the reason why we call them bilinear.
- For fixed, all , and any real constant , linearity in the first argument means the following:
- For fixed, all , and any real constant , linearity in the second argument means the following:
Eigen-everything
Eigenvectors: “natural” directions of the matrix/linear transformation that represent only a scaling/stretch.
Diagonalize
A square matrix is called diagonalizable if there exists a diagonal matrix and an invertible matrix such that:
If is a matrix, then it is diagonalizable if and only if there exists a basis of that consists of eigenvectors of .
We can break this down into two possible cases:
-
Case 1: If has two distinct eigenvalues, then it is indeed diagonalizable. This is because two distinct eigenvalues will give rise to two linearly independent eigenvectors (one for each eigenvalue).
So, for a matrix with eigenvalues and and corresponding eigenvectors and , we have
-
Case 2: If we get a double root of the characteristic equation, the matrix will be diagonalizable only if we can find exactly two linearly independent eigenvectors corresponding to , which may or may not be possible. Another way of saying this is that the corresponding eigenspace must be of dimension 2.
Geometrical Interpretation:
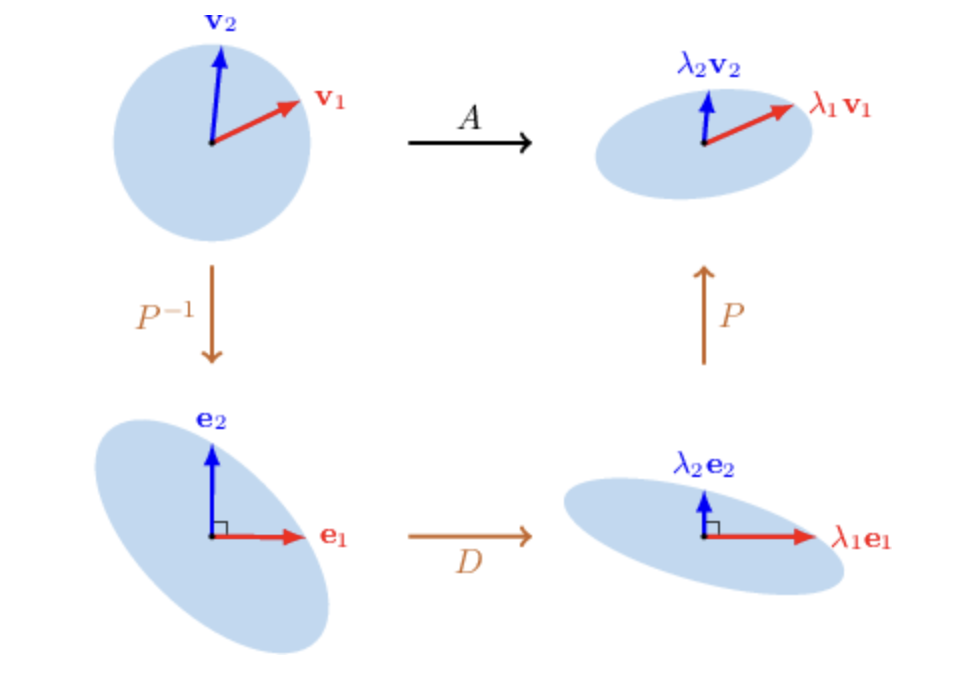
-
The matrix changes the coordinates of any vector of the plane from the standard basis to the basis of eigenvectors .
-
The diagonal matrix scales the 1st and 2nd coordinates by and , respectively.
-
Finally, the matrix changes the coordinates of the result back to the standard basis.
Matrix Powers
From diagonalization we have:
This generalizes to: